

Appendix A. Details on Scan Data Set, Manual Reviews, Algorithm Classification Methods, and Supplemental Scan Results
This appendix provides additional information about the data set, methods, and results used in the environmental scan to supplement the discussion in Chapters 2 and 3. This appendix first describes the composition of the scan data set, followed by details on the number of manual reviews conducted and measures of interrater agreement. The appendix then provides information on machine learning methods and algorithm accuracy and, last, supplemental scan results providing confidence intervals for the tables reported in Chapter 3 and scan results by year.
Composition of the Scan Data Set
As discussed in Chapter 2, the study team drew on two primary data sources: publicly available databases of federally funded grant projects, and contract and grant data provided to RAND directly by federal agencies. Table A.1 on the following page breaks down the projects in the scan data set by source, funder, and type.
Table A.1. Number of Projects in Scan Data Set, by Type, Source, and Funder
| Type | Source | ACL | AHRQ | CDC | CMS | NIH | VHA | All Agencies |
|---|---|---|---|---|---|---|---|---|
| Grants | RePORTER | 0 | 850 | 1,092 | 0 | 79,677 | 2,748 | 85,531 |
| Agency-provided | 68 | 33 | 35 | 0 | 0 | 661 | 797 | |
| Overlapa | 0 | 33 | 34 | 0 | 0 | 396 | 463 | |
| Total grants | 68 | 850 | 1,093 | 0 | 79,677 | 3,013 | 86,865 | |
| Contracts | RePORTER | 0 | 0 | 0 | 0 | 6,614 | 0 | 6,615 |
| Agency-providedb | 0 | 305 | 0 | 75 | 0 | 0 | 380 | |
| Total contracts | 0 | 305 | 0 | 75 | 6,614 | 0 | 6,995 | |
| Total projects | 68 | 1,155 | 1,093 | 75 | 86,321 | 3,013 | 93,075 |
Note: The grant and contracts numbers are based on the scan data set, following merging of nonunique project records and the exclusion of projects that met any of the following criteria: (a) projects with pre-FY 2012 start dates, (b) projects with post-FY 2018 start dates, (c) projects missing abstracts, (d) projects with RePORTER activity codes related to research infrastructure and support, and (e) projects conducted intramurally by agency staff. Refer to Chapter 2 for additional details. The All Agencies and All Projects Totals include 1 ACF contract, 185 other ACF projects of unknown type, 9 ATSDR grants, 1,155 FDA grants, and 30 NIH projects of unknown type.
a Agency-provided grants also in RePORTER. Not included in sum of Total grants.
b No overlap with RePORTER.
Table A.2 describes the extent of the grants and contracts included in the scan data set from each funder, focusing in particular on whether the data set appears to include all, some, or no grants or contracts from each funding agencies. For each agency, these determinations were based on whether project data were available in RePORTER and whether there were any indications that these RePORTER data were incomplete.
While projects available in RePORTER potentially represent complete research grant and contract portfolios for a given funding agency, the projects provided directly by the agencies only represented those grants or contracts that were identified by that agency as likely being in-scope as HSR, PCR, and/or MTD. In addition, for both the CDC and the VHA, there were indications that the grants included in the scan data set from RePORTER were not fully representative of those agencies’ research portfolios. A large proportion of the CDC research grants listed in RePORTER were missing abstracts and thus could not be included in the scan data set.
Table A.2. Extent of Projects Included in the Scan Data Set, by Type and Funder
| Funder | Grants | Contracts |
|---|---|---|
| ACL | Data set contains grants selected by agency contacts as likely in-scope for this study, but not the agency’s full grant portfolio. | Agency does not award research contracts. |
| AHRQ | Data set appears to include the full research grant portfolio. Data set includes all AHRQ-funded grants in RePORTER, which includes all grants in the AHRQ’s Project Research Online Database as well as all agency-provided grants. | Data set contains contracts selected by agency contacts as likely in-scope for this study, but not the agency’s full contract portfolio. |
| CDC | Data set contains grants selected by agency contacts as likely in-scope for this study, as well as all CDC-funded grants in RePORTER, except for a large proportion that were missing abstracts. | Agency does not award research contracts. |
| CMS | Agency does not award research grants. | Data set contains contracts selected by agency contacts as likely in-scope for this study, but not the agency’s full contract portfolio. |
| NIH | Data set appears to include the full research grant portfolio. Data set includes all NIH-funded grants in RePORTER. | Data set appears to include the full research contract portfolio. Data set includes all NIH-funded contracts in RePORTER. |
| VHA | Data set contains grants selected by agency contacts as likely in-scope for this study, as well as all VHA-funded grants in RePORTER. However, a substantial proportion of the grants directly provided by the VHA were not present in RePORTER (matching against grant number, PI, and/or abstract). This suggests that not all VHA grants may be entered into RePORTER, and thus our data set may be missing some VHA research grants. | Agency does not award research contracts. |
Data for the VHA were more complicated. The RePORTER database did not include all the grants provided by the agency, and the agency-provided grants did not include all projects from the RePORTER database identified as in-scope by the study. Thus, it is unclear whether the combined data obtained from the VHA and the RePORTER database represent the complete portfolio of VHA projects including all out-of-scope projects.
Excluded National Institutes of Health Activity Codes
Projects that focused on research infrastructure, career development, conferences, and service provision were excluded from the environmental scan data set based on their NIH activity code. The specific NIH activity codes that were excluded in this way are listed below:
- A03, A10, A22
- B04
- C06, C12, C13, C8A, C8B, C8C, C8D
- D04, D06, D09, D11, D18, D19, D33, D34, D43, D57
- F05, F30, F31, F32, F33, F99
- G01, G02, G05
- H1G, H1M, H1U, H1W, H2A, H2Q, H30, H33, H34, H37, H3A, H3D, H3G, H3H, H46, H47, H49, H4A, H4B, H54, H56, H61, H65, H6M, H76, H7M, H80, H84, H87, H98, HS0
- K01, K02, K05, K07, K08, K12, K18, K22, K23, K24, K25, K26, K43, K76, K99
- P20, P2C, P30, P40, P50, P60, PN2
- R13, R15, R25, R35, R36, R37, R3
- T08, T0B, T12, T15, T23, T32, T34, T35, T37, T42, T90, T94, TL1
- U13, UL1
- X02, X08, X09, X10.
Research Portfolios by Type, Funding Agency, and Year
The four tables below show the relative proportion of contracts as compared to grants for each funding agency, by year, for both the entire scan data set (Tables A.3 and A.4) and for only the set of projects that were found to be in-scope for the study (Tables A.5 and A.6).
Table A.3. Project Type, by Funding Agency
| ACL | AHRQ | CDC | CMS | NIH | VHA | All Agenciesa | |
|---|---|---|---|---|---|---|---|
| Total projects in scan data setb | 68 | 1,155 | 1,093 | 75 | 86,321 | 3,013 | 93,075 |
| Contracts | 0(0%) | 305 (26%) |
0 (0%) |
75& (100%) |
0(0%) | 0(0%) | 6,995 (8%) |
| Grants | 68 (100%) |
850 (74%) |
1,093 (100%) |
0(0%) | 1,155 (100%) |
3,013 (100%) |
85,865 (92%) |
a The “All Agencies” contract and grant numbers include projects from the six agencies in the table as well as 1,155 FDA grants, 9 ATSDR grants, and 1 ACF contract. There were also 185 ACF projects that were missing project type information in Reporter; these were counted in the “All Agencies” total project number but not in the contract or grant project numbers. The FDA, ATSDR, and ACF project numbers are not reported separately since we did not perform member-checking of those results with the agencies as required by the scan methodology.
b The “Total Projects” numbers are based on the scan data set, which includes data from the RePORTER database and directly from individual agencies, following merging of nonunique project records and the exclusion of projects that met any of the following criteria: (a) projects with pre-FY 2012 start dates; (b) projects with post-FY 2018 start dates; (c) projects missing abstracts; (d) projects with RePORTER activity codes related to research infrastructure and support; and (e) projects conducted intramurally by agency staff. Refer to Chapter 2 for additional details.
Table A.4. Percent of Projects That Are Contracts, by Funding Agency and Year
| Year | ACL | AHRQ | CDC | CMS | NIH | VHA | All Agenciesa |
|---|---|---|---|---|---|---|---|
| 2012 | (No projects) | 24% | 0% | 100% | 8% | 0% | 8% |
| 2013 | 0% | 34% | 0% | 100% | 10% | 0% | 10% |
| 2014 | 0% | 16% | 0% | 100% | 9% | 0% | 8% |
| 2015 | 0% | 30% | 0% | 100% | 9% | 0% | 8% |
| 2016 | 0% | 26% | 0% | 100% | 8% | 0% | 8% |
| 2017 | 0% | 22% | 0% | 100% | 7% | 0% | 7% |
| 2018 | 0% | 26% | 0% | 100% | 4% | 0% | 4% |
| All Years | 0% | 26% | 0% | 100% | 8% | 0% | 8% |
a The “All Agencies” percentages include projects from the six agencies in the table as well as FDA grants, ATSDR grants, and an ACF contract. The latter is not reported separately since we did not perform member-checking of those results with the agencies as required by the scan methodology.
Table A.5. In-Scope Project Type, by Funding Agency
| ACL | AHRQ | CDC | CMS | NIH | VHA | All Agenciesa | |
|---|---|---|---|---|---|---|---|
| Total in-scope (HSR/PCR/MTD) projectsb | 58 | 915 | 328 | 74 | 8,707 | 889 | 10,989 |
| Contracts | 0(0%) | 175 (19%) |
0(0%) | 74 (100%) |
387 (4%) |
0(0%) | 636 (6%) |
| Grants | 58 (100%) |
740 (81%) |
328 (100%) |
0(0%) | 8,320 (96%) |
889 (100%) |
10,353 (94%) |
a The “All Agencies” percentages include projects from the six agencies in the table as well as in-scope FDA grants. The latter are not reported separately since we did not perform member-checking of those results with the agency as required by the scan methodology.
b The “Total Projects” numbers are based on the scan data set, which includes data from the RePORTER database and directly from individual agencies, following merging of nonunique project records and the exclusion of projects that met any of the following criteria: (a) projects with pre-FY 2012 start dates, (b) projects with post-FY 2018 start dates, (c) projects missing abstracts, (d) projects with RePORTER activity codes related to research infrastructure and support, and (e) projects conducted intramurally by agency staff. Refer to Chapter 2 for additional details.
Table A.6. Percent of In-Scope Projects That Are Contracts, by Funding Agency and Year
| Year | ACL | AHRQ | CDC | CMS | NIH | VHA | All Agenciesa |
|---|---|---|---|---|---|---|---|
| 2012 | (No projects) | 15% | 0% | 100% | 5% | 0% | 8% |
| 2013 | 0% | 28% | 0% | 100% | 4% | 0% | 10% |
| 2014 | 0% | 7% | 0% | 100% | 5% | 0% | 8% |
| 2015 | 0% | 22% | 0% | 100% | 6% | 0% | 8% |
| 2016 | 0% | 20% | 0% | 100% | 6% | 0% | 8% |
| 2017 | 0% | 17% | 0% | 100% | 4% | 0% | 7% |
| 2018 | 0% | 18% | 0% | 100% | 2% | 0% | 4% |
| All Years | 0% | 19% | 0% | 100% | 4% | 0% | 8% |
a The “All Agencies” percentages include projects from the six agencies in the table as well as in-scope FDA grant projects. The latter are not reported separately since we did not perform member-checking of those results with the agency as required by the scan methodology.
Number of Manual Reviews and Interrater Agreement
The study team conducted manual reviews of 3,139 projects. A total of 2,880 of these reviewed projects were eventually included in the final scan data set of 93,075 project records. The remaining 259 reviewed projects were excluded from the final data set due to their start date falling outside the bounds of the FY 2012 to 2018 study period. While these 259 projects were not counted in the final classification results, they were still used, together with the other manually reviewed projects, to train the machine learning algorithm and test its accuracy.
A total of 2,790 projects (out of the 3,139 total reviewed projects) received reviews that covered each of the overall HSR, PCR, and MTD categories and thus were sufficient to determine whether they were in or out scope for the scan. A total of 1,868 of these 2,790 projects received full reviews that covered all of the classification categories. An additional 737 of these 2,790 projects received reviews of all the classification categories except Toolkit Development, which was added after initial reviews were complete. A further 185 of these 2,790 projects received reviews that did not cover one or more of the other classification categories. And another 349 of the total 3,139 projects received narrowly targeted reviews that covered a smaller subset of individual categories and domains. This information on the varying extents to which these projects were reviewed, including how these groups do and do not overlap, is depicted below in Figure A.1.
Figure A.1. Manually Reviewed Projects Grouped by Extent of Reviews
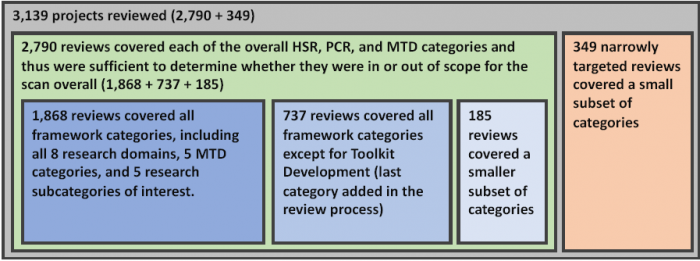
Some projects were reviewed more than once. A random sample of roughly 200 projects were examined separately by two reviewers in order to measure the degree of interrater agreement on each category, as shown in Table A.7 on the following page. The study team also updated coding guidelines in the middle of the reviewing process for some of the categories after resolving issues that arose in the initial set of reviews. Following this, 711 projects were re-reviewed to ensure their consistency with the updated guidelines.
The study team manually reviewed all 1,176 projects that were directly provided to us by ACL, AHRQ, CDC, CMS, and the VHA and determined whether they were in or out-of-scope for the scan.1 The final scan data set, which contained 93,075 project records, also included 91,899 projects that were not directly provided by any agency and were instead derived from the RePORTER database. We manually reviewed 1,406 of these projects to determine whether they were in or out-of-scope. The remaining 90,493 projects were classified by the machine learning algorithm.
1 These 1,176 projects include only those agency-provided projects that fell within the initial bounds of the scan. This number does not include agency-provided projects that were excluded due to missing information or were excluded due to having a start date outside of the FY 2012 to 2018 time period.
Table A.7. Interrater Agreement
| Classification Category | Number Reviewed | Number of Double-Coded Projects | Agreed Negative | Disagreed | Agreed Positive | Percent Agreement | Kappa |
|---|---|---|---|---|---|---|---|
| HSR | 394 | 197 | 83 | 18 | 96 | 91% | 0.82 |
| PCR | 394 | 197 | 169 | 15 | 13 | 92% | 0.59 |
| MTD | 386 | 193 | 141 | 16 | 36 | 92% | 0.76 |
| In-Scope (HSR, PCR, and/or MTD) | 386 | 193 | 65 | 13 | 115 | 93% | 0.86 |
| Quality of Care | 390 | 195 | 86 | 40 | 69 | 79% | 0.59 |
| Cost and Utilization | 382 | 191 | 137 | 24 | 30 | 87% | 0.64 |
| Access to Care | 372 | 186 | 130 | 31 | 25 | 83% | 0.51 |
| Equity | 388 | 194 | 157 | 17 | 20 | 91% | 0.65 |
| Systems of Care | 388 | 194 | 89 | 25 | 80 | 87% | 0.74 |
| Financing of Care | 388 | 194 | 188 | 0 | 6 | 100% | 1.00 |
| Social Factors | 380 | 190 | 161 | 19 | 10 | 90% | 0.46 |
| Personal Preferences and Behaviors | 388 | 194 | 117 | 33 | 44 | 83% | 0.61 |
| Definitive Health Outcomes | 362 | 181 | 132 | 31 | 18 | 83% | 0.43 |
| Aging | 362 | 181 | 166 | 7 | 8 | 96% | 0.68 |
| Multimorbiditya | 362 | 181 | 164 | 13 | 4 | 93% | 0.34 |
| Patient Safety | 362 | 181 | 157 | 14 | 10 | 92% | 0.55 |
| Pediatrics | 362 | 181 | 175 | 1 | 5 | 99% | 0.91 |
| Prevention | 360 | 180 | 125 | 25 | 30 | 86% | 0.62 |
| HIT Applications and Tools | 386 | 193 | 166 | 13 | 14 | 93% | 0.65 |
| Model Development and Validation | 386 | 193 | 156 | 13 | 24 | 93% | 0.75 |
| Toolkit Development | 330 | 165 | 153 | 3 | 9 | 98% | 0.85 |
| Evidence Review and Synthesis | 386 | 193 | 191 | 0 | 2 | 100% | 1.00 |
| Simulation Modeling | 384 | 192 | 187 | 2 | 3 | 99% | 0.74 |
a While some projects were classified as multimorbidity studies, this category was not reported in the overall results due to its low kappa measures of interrater agreement (as seen in this table) and machine learning accuracy.
Machine Learning Method Details
The machine learning algorithm relied on a logistic regression model, trained on the manual reviews, to produce classifications for the projects that were not manually reviewed. The algorithm used the narrative text found in the project abstract or description field to generate classification scores for each project and category based on a logistic regression model. A list of 179 less meaningful, commonly used English words (such as “a,” “the,” “it,” “that,” “is”) were removed from all abstracts before processing (NLTK Corpora, undated).2
We employed a straightforward “bag of words” approach to processing text for machine learning analysis. In this approach, the algorithm did not take into account sentence structure or relationships between words, but rather simply checked to see how frequently particular words and phrases are present in an abstract. Only more frequently used words and two-word phrases were selected for inclusion in the model. We set our algorithm to include any words and phrases found in any of three overlapping lists: (1) the 2,000 words and phrases that were most common in all abstracts, (2) the 2,000 words and phrases that were most common in project abstracts manually reviewed as positive for a particular category, and (3) the 2,000 words and phrases that were most common in project abstracts manually reviewed as negative for a particular category. Word frequencies were then weighted and normalized using the commonly used term-frequency inverse document-frequency function. As described by Fabrizio Sebastiani, “This function embodies the intuitions that (i) the more often a term occurs in a document, the more it is representative of its content, and (ii) the more documents a term occurs in, the less discriminating it is” (Sebastiani, 2002).
Within the logistic regression model, the words and two-word phrases that occurred most frequently across all abstracts were assigned coefficients according to their association with positive and negative manual classifications in the training set. Remaining project abstracts were then input into the model, which produced a classification score ranging from 0.0 (not likely to meet category criteria) to 1.0 (highly likely to meet category criteria) for each project. The algorithm was run five separate times following a stratified K-fold cross-validation approach, with one-fifth of the manually reviewed data reserved each time in order to test algorithm accuracy and identify false positives and false negatives, leaving the algorithm to be trained on the other four-fifths of the manually reviewed data (Kohavi, 1995).
While many project classification scores clustered at one end or the other of the 0.0–1.0 range of scores, many other projects received scores more in the middle of the range, indicating a level of algorithmic uncertainty about whether that project should be classified as meeting the criteria for a particular category or not. To generate actual estimates of the number of projects in each category for the scan, however, we had to classify projects as either counted in or out of the category. We did this using a numeric decision threshold, with only projects receiving a classification score above that threshold counted as meeting the criteria for that category.
The final estimates of the number of projects in each category are highly sensitive to which decision threshold is chosen to base classifications on. Various strategies can be employed to set classification thresholds, with each appropriate to different purposes. Some of these strategies, such as the naive use of a 0.5 threshold, or selecting the threshold that maximizes the sum of sensitivity and specificity, perform poorly when attempting to accurately estimate the prevalence of a particular subtype in an overall population, especially for subtypes that are uncommon (Freeman and Moisen, 2008). Instead, approaches to threshold setting that attempt to balance the numbers of expected false positive classifications against the number of false negative classifications are more likely to produce an accurate prevalence estimate (Smits, 2010). This “cost-balancing” approach was the one that we used.
To set a threshold in this way, we examined the classification scores produced by the machine learning against the results of the manual reviews, which were stratified into two overall subsets of manually reviewed data:
- The first subset consisted of all the manual reviews that we conducted on project records that we had initially chosen for review based on their already being identified as likely to be in-scope for our scan. This included reviewed projects that met any one of the following criteria:
- The project was listed in HSRProj.
- The project was directly provided by funding agencies in response to our data call.
- The project was listed in RePORTER as part of the NIH Research, Condition, and Disease Categorization of “Health Services.”
- The project was selected for manual review based on its being classified as in scope by an earlier version of the machine learning algorithm.
- The second subset consisted of all the manual reviews that we conducted on a random sample of project records from NIH RePORTER. For these projects, none of the reasons listed above for suspecting that a project might a priori be in-scope applied.
For each of these subsets of manual reviews, we chose a decision threshold that produced an equal number of algorithmically classified false positives and false negatives when compared against the manually reviewed classifications. These two decision thresholds were then applied to the rest of the data set, similarly stratified into the subset of data that was previously identified as potentially in-scope and the subset of data from RePORTER that was not identified as such, to produce classifications for all the projects that had not been manually reviewed.
2 The list of excluded words is from NLTK, “Stopwords Corpus: English,” undated.
Algorithm Accuracy
We compared the machine learning algorithm’s classifications against the manual classifications for each category. Table A.8 provides various measures of how accurately the machine learning algorithm was able to reproduce the manual classifications for each category.
Table A.8. Machine Learning Algorithm Accuracy
| Classification Category | No. Reviewed Manually | True Pos. | True Neg. | False Pos. | False Neg. | Percent Agreem't | Sensitivity | Specificity | Kappa |
|---|---|---|---|---|---|---|---|---|---|
| HSR | 2,760 | 1,165 | 1,394 | 99 | 102 | 93% | 92% | 93% | 0.85 |
| PCR | 2,693 | 161 | 2,359 | 86 | 87 | 94% | 65% | 96% | 0.62 |
| MTD | 2,582 | 287 | 2,053 | 118 | 124 | 91% | 70% | 95% | 0.65 |
| In-Scope (HSR, PCR, and/or MTD) | 2,583 | 1,184 | 1,005 | 194 | 200 | 85% | 86% | 84% | 0.69 |
| Quality of Care | 2,629 | 830 | 1,426 | 186 | 187 | 86% | 82% | 88% | 0.70 |
| Cost and Utilization | 2,598 | 283 | 2,032 | 137 | 146 | 89% | 66% | 94% | 0.60 |
| Access to Care | 2,460 | 169 | 1,961 | 164 | 166 | 87% | 50% | 92% | 0.43 |
| Equity | 2,632 | 168 | 2,220 | 123 | 121 | 91% | 58% | 95% | 0.53 |
| Organization of Care | 2,638 | 880 | 1,449 | 151 | 158 | 88% | 85% | 91% | 0.75 |
| Financing of Care | 2,624 | 88 | 2,469 | 33 | 34 | 97% | 72% | 99% | 0.71 |
| Social Factors | 2,577 | 151 | 2,180 | 122 | 124 | 90% | 55% | 95% | 0.50 |
| Personal Preferences and Behaviors | 2,632 | 409 | 1,875 | 173 | 175 | 87% | 70% | 92% | 0.62 |
| Definitive Health Outcomes | 2,460 | 174 | 1,994 | 148 | 144 | 88% | 55% | 93% | 0.48 |
| Aging | 2,469 | 160 | 2,183 | 64 | 62 | 95% | 72% | 97% | 0.69 |
| Multimorbiditya | 2,459 | 36 | 2,289 | 67 | 67 | 95% | 35% | 97% | 0.32 |
| Patient Safety | 2,459 | 134 | 2,154 | 86 | 85 | 93% | 61% | 96% | 0.57 |
| Pediatrics | 2,459 | 69 | 2,348 | 21 | 21 | 98% | 77% | 99% | 0.76 |
| Prevention | 2,460 | 261 | 1,890 | 152 | 157 | 87% | 62% | 93% | 0.55 |
| HIT Applications and Tools | 2,586 | 100 | 2,309 | 89 | 88 | 93% | 53% | 96% | 0.49 |
| Model Develop-ment and Validation | 2,583 | 175 | 2,236 | 86 | 86 | 93% | 67% | 96% | 0.63 |
| Toolkit Development | 1,760 | 20 | 1,690 | 25 | 25 | 97% | 44% | 96% | 0.43 |
| Simulation Modeling | 2,581 | 9 | 2,515 | 29 | 28 | 98% | 24% | 99% | 0.23 |
| Evidence Review and Synthesis | 2,582 | 100 | 2,442 | 21 | 19 | 98% | 84% | 99% | 0.83 |
a While some projects were classified as multimorbidity studies, this category was not reported in the overall results due to its low kappa measures of interrater agreement and machine learning accuracy (as seen in this table).
In this table, the true positive column displays how many projects were classified positive by both the algorithm and the manual reviewer for each domain. Similarly, the true negative column displays how many projects were classified negative by both algorithm and reviewer. The false positive column gives the number of projects that the algorithm classified as positive but were manually reviewed as negative, and the false negative column gives the number of projects that the algorithm classified negative but were manually reviewed as positive. These numbers were then used to calculate the overall accuracy measures of percent agreement, sensitivity, specificity, and kappa.
Despite the existence of misclassifications, if the number of false positives is balanced by an equal number of false negatives (as our algorithm attempts to do), the resulting overall estimate of the number of projects in each classification category will still be valid.
Scan Results by Funding Agency, Including Confidence Intervals
Tables A.9–A.12 are the same as Tables 3.2–3.5 in Chapter 3, with the addition of 95-percent confidence intervals. These confidence intervals are calculated based on the variance observed across multiple machine learning algorithm runs, with each run featuring a different training data set sampled from the full set of manual reviews in the stratified fivefold cross-validation process, as described earlier in Appendix A. These confidence intervals do not take into account any variation in results that might occur during the manual review process; the manual review results are rather treated as fixed.
For most classification categories, the results for ACL and CMS were based entirely on manual reviews, and thus the overall result, the lower confidence interval bound, and the upper confidence interval bound are all identical. AHRQ, CDC, NIH, and VHA results are based on a mix of manual reviews and algorithm results, however, and therefore feature a varying range of confidence intervals. The confidence intervals are wider when any of the following three factors are present: (1) the results include fewer manual classifications and more algorithm classifications; (2) the algorithm is less accurate for a particular category; (3) the results include fewer project abstracts that clearly fall inside or outside a category and more abstracts that appear to fall somewhere in between.
Table A.9. HSR, PCR, and Methods and Tool Development Projects, by Funding Agency, Mean Estimate, and 95-Percent Confidence Interval
| ACL | AHRQ | CDC | CMS | NIH | VHA | All Agenciesa | |
|---|---|---|---|---|---|---|---|
| Total projects in scan data setb | 68 | 1,155 | 1,093 | 75 | 86,321 | 3,013 | 93,075 |
| Projects classified as HSR | 53 (78%) 53-53 |
653 (57%) 628-677 |
267 (24%) 251-282 |
57 (78%) 57-57 |
6,891 (8%) 6,745–7,036 |
794 (26%) 784–803 |
8,767 (9%) 8,621–8,912 |
| Projects classified as PCR | 2(3%) 2-2 |
149 (13%) 35–162 |
28 (3%) 20-35 |
9 (12%) 9-9 |
750 (1%) 680–819 |
150 (5%) 145–154 |
1,090 (1%) 1,031–1,148 |
| Projects classified as HCR and/or PCR | 53 (78%) 53-53 |
668 (58%) 643–692 |
268 (25%) 252-283 |
58 (77%) 58-58 |
6,948 (8%) 6,803–7,092 |
797 (26%) 87–806 |
8,845 (9%) 549–834 |
| Projects classified as MTD | 26 (38%) 26-26 |
432 (37%) 403–460 |
104 (10%) 92-115 |
17 (23%) 17-17 |
3,501 (4%) 3,370–3,631 |
310 (10%) 284–335 |
4,416 (5%) 4,257–4,574 |
| Projects classified in-scope (HSR, PCR and/or MTD) | 58 (85%) 58-58 |
915 (79%) 911–918 |
328 (30%) 262-393 |
74 (99%) 74-74 |
8,707 (10%) 8,312–9,101 |
889 (30%) 870–907 |
11,045 (12%) 10,640– 11,449 |
Note: These results are based on a combination of manual reviews and machine learning–based automated classification of projects in the scan data set. For additional details, please refer to Chapter 2 and Appendix A.
a The “All Agencies” tally includes projects from the six agencies listed in the table as well as the FDA, ACF, and ATSDR projects listed in RePORTER, which are not reported separately due to our inability to validate results with these two agencies. Nevertheless, we classified 15 (1 percent) out of 1,155 FDA projects as in-scope and classified 46 (25 percent) out of 186 ACF projects as in-scope. Another nine ATSDR projects were also reviewed; none were classified as in-scope.
b The “Total Projects” numbers are based on the consolidated scan data set, which includes data from the RePORTER database and provided by individual agencies, following merging of nonunique project records and the exclusion of projects that met any of the following criteria: (a) projects with pre-FY 2012 start dates, (b) projects with post-FY 2018 start dates, (c) projects missing abstracts, (d) projects with RePORTER activity codes related to research infrastructure and support, (e) projects conducted intramurally by agency staff. Refer to Chapter 2 for additional details on these exclusions. Nonunique project records were identified using core project numbers, with project renewals (type 2), supplements (type 3), and change of grantees (type 7) treated as separate projects and thus excluded from merging.
Table A.10. HSR and/or PCR Projects, by Research Domain and Funding Agency, Mean Estimate, and 95-Percent Confidence Interval
| Research Domain | ACL | AHRQ | CDC | CMS | NIH | VHA | All Agenciesa |
|---|---|---|---|---|---|---|---|
| Total HCR and/or PCR projects | 53 | 668 | 268 | 58 | 6,948 | 797 | 8,845 |
| Quality of Care | 46 (87%) 46-46 |
535 (80%) 504-565 |
214 (80%) 190-237 |
52 (90%) 52-52 |
6,207 (89%) 5,953–6,460 |
695 (87%) 677–712 |
7,795 (88%) 7,525–8,064 |
| Cost and Utilization | 9 (17%) 9-9 |
262 (39%) 243-280 |
98 (37%) 83-112 |
51 (88%) 51-51 |
1,852 (27%) 1,602–2,101 |
192 (24%) 185-198 |
2,471 (28%) 2,203–2,738 |
| Access to Care | 18 (34%) 18-18 |
90 (13%) 79-100 |
97 (36%) 83-110 |
11 (19%) 11-11 |
1,803 (26%) 1,670–1,935 |
312 (39%) 293-330 |
2,337 (26%) 2,205–2,468 |
| Equity | 8 (15%) 8-8 |
95 (14%) 81-108 |
93 (35%) 83-102 |
6 (10%) 6-6 |
2,319 (33%) 2,173–2,464 |
125 (16%) 115-134 |
2,657 (30%) 2,521–2,792 |
| Organization of Care | 45 (85%) 45-45 |
602 (90%) 573-630 |
233 (87%) 227-328 |
43 (74%) 43-43 |
5,985 (86%) 5,801–6,168 |
745 (93%) 730–759 |
7,702 (87%) 7,502–7,901 |
| Financing of Care | 8 (15%) 8-8 |
89 (13%) 83-94 |
11 (4%) 8-13 |
38 (66%) 38-38 |
172 (2%) 157-186 |
20 (3%) 20-20 |
339 (4%) 317-360 |
| Social Factors | 21 (40%) 21-21 |
104 (16%) 91-116 |
74 (28%) 69-78 |
1(2%) 1-1 |
1,987 (29%) 1,874–2,099 |
146 (18%) 130-161 |
2,350 (27%) 2,220–2,479 |
| Personal Preferences and Behaviors | 33 (62%) 33-33 |
177 (26%) 161-192 |
151 (56%) 136-165 |
8 (14%) 8-8 |
5,280 (76%) 5,178–5,381 |
475 (60%) 454-495 |
6,142 (69%) 6,028–6,255 |
Note: These results are based on a combination of manual reviews and machine learning–based automated classification of projects in the scan data set. For additional details, please refer to Chapter 2 and Appendix A.
a The “All Agencies” tally includes projects from the six agencies listed in the table as well as the FDA and ACF projects that are listed in RePORTER and are classified as HSR and/or PCR.
Table A.11. HSR and/or PCR Projects, by Research Areas of Interest and Funding Agency, Mean Estimate, and 95-Percent Confidence Interval
| Area of All Interest |
ACL | AHRQ | CDC | CMS | NIH | VHA | All Agenciesa |
|---|---|---|---|---|---|---|---|
| Total HCR and/or PCR projects | 53 | 668 | 268 | 58 | 6,948 | 797 | 8,845 |
| Definitive Health Outcomes | 11 (21%) 11–11 |
124 (19%) 93–154 |
40 (15%) 28–51 |
21 (36%) 20–21 |
1,953 (28%) 1,785– 2,120 |
299 (38%) 281–316 |
2,455 (28%) 2,279–2,630 |
| Aging | 11 (21%) 11–11 |
149 (22%) 140–157 |
42 (15%) 31–52 |
44 (76%) 44–44 |
1,281 (18%) 1,202– 1,359 |
140 (18%) 135–144 |
1,681 (19%) 1,591–1,770 |
| Patient Safety | 3 (6%) 3–3 |
270 (40%) 253–286 |
77 (29%) 71–82 |
4 (7%) 4–4 |
855 (12%) 777–932 |
148 (19%) 142–153 |
1,377 (16%) 1,299–1,454 |
| Pediatrics | 3 (6%) 3–3 |
67 (10%) 62–71 |
51 (19%) 48–53 |
1(2%) 1–1 |
1,308 (19%) 1,194–1,421 |
0(0%) 0–0 |
1,457 (16%) 1,335–1,578 |
| Prevention | 5 (9%) 5–5 |
250 (37%) 235–264 |
221 (82%) 208–233 |
10 (17%) 10–10 |
4,918 (71%) 4,618–5,217 |
303 (38%) 282–323 |
5,732 (65%) 5,415–6,048 |
Note: These results are based on a combination of manual reviews and machine learning–based automated classification of projects in the scan data set. For additional details, please refer to Chapter 2 and Appendix A.
a The “All Agencies” tally includes projects from the six agencies listed in the table as well as the FDA and ACF projects that are listed in RePORTER and are classified as HSR and/or PCR.
Table A.12. All In-Scope Projects, by Methods and Tool Development/Methods of Interest Categories and Funding Agency, Mean Estimate, and 95-Percent Confidence Interval
| MTD and Methods of Interest All Categories |
ACL | AHRQ | CDC | CMS | NIH | VHA | All Agenciesa |
|---|---|---|---|---|---|---|---|
| Total projects classified in-scope | 58 | 915 | 328 | 74 | 8,707 | 889 | 11,045 |
| HIT applications and tools | 10 (17%) 10–10 |
238 (26%) 224–251 |
21 (6%) 15–26 |
5 (7%) 5–5 |
1,152 (13%) 1,082–1,221 |
84 (9%) 78–89 |
1,514 (14%) 1,439–1,588 |
| Model development and validation | 17 (29%) 17–17 |
212 (23%) 192–231 |
52 (16%) 42–61 |
17 (23%) 17–17 |
2,069 (24%) ,922–2,215 |
193 (22%) 180–205 |
2,579 (23%) 2,431–2,726 |
| Toolkit development | 7 (12%) 6–7 |
79 (9%) 65–92 |
15 (5%) 4–25 |
0(0%) 0–0 |
153 (2%) 98–207 |
39 (4%) 30–47 |
294 (3%) 211–376 |
| Evidence review and synthesis | 5 (9%) 5–5 |
120 (13%) 115–124 |
7 (2%) 2–11 |
3(4%) 3–3 |
352 (4%) 234–469 |
13 (1%) 10–15 |
506 (5%) 387–624 |
| Simulation modeling | 0(0%) 0–0 |
18 (2%) 13–22 |
9 (3%) 5–12 |
0(0%) 0–0 |
380 (4%) 293–466 |
15 (2%) 13–16 |
423 (4%) 329–516 |
Note: These results are based on a combination of manual reviews and machine learning–based automated classification of projects in the scan data set. For additional details, please refer to Chapter 2 and Appendix A.
a The “All Agencies” tally includes projects from the six agencies listed in the table as well as the FDA and ACF projects that are listed in RePORTER and are classified as HSR and/or PCR.
Scan Results by Year
Finally, Table A.13 provides the scan results by year.
Table A.13. In-Scope Projects, by Overall Category and Year
| Category | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 |
|---|---|---|---|---|---|---|
| HSR | 1,287 | 1,273 | 1,299 | 1,224 | 1,323 | 1,188 |
| PCR | 99 | 144 | 199 | 153 | 189 | 169 |
| MTD | 628 | 645 | 582 | 665 | 633 | 585 |
| In-scope (HSR, PCR, and/or MTD) | 1,621 | 1,600 | 1,592 | 1,565 | 1,673 | 1,481 |
| Quality of Care | 1,155 | 1,086 | 1,115 | 1,070 | 1,202 | 1,087 |
| Cost and Utilization | 370 | 360 | 349 | 318 | 420 | 338 |
| Access to Care | 331 | 327 | 320 | 335 | 373 | 325 |
| Equity | 430 | 375 | 386 | 363 | 436 | 378 |
| Organization of Care | 1,112 | 1,118 | 1,140 | 1,085 | 1,159 | 1,027 |
| Financing of Care | 39 | 49 | 33 | 59 | 73 | 54 |
| Social Factors | 349 | 328 | 311 | 313 | 385 | 376 |
| Personal Preferences and Behaviors | 937 | 825 | 871 | 893 | 920 | 819 |
| Definitive Health Outcomes | 370 | 318 | 349 | 313 | 398 | 338 |
| Aging | 198 | 226 | 211 | 199 | 273 | 223 |
| Patient Safety | 176 | 177 | 193 | 184 | 204 | 196 |
| Pediatrics | 247 | 199 | 210 | 226 | 199 | 208 |
| Prevention | 883 | 755 | 825 | 881 | 833 | 761 |
| HIT Applications and Tools | 244 | 226 | 208 | 249 | 200 | 197 |
| Model Development and Validation | 351 | 346 | 340 | 401 | 373 | 360 |
| Evidence Review and Synthesis | 66 | 72 | 41 | 86 | 72 | 71 |
| Simulation Modeling | 79 | 80 | 59 | 47 | 62 | 41 |
Note: These results are based on a combination of manual reviews and machine learning–based automated classification of projects in the scan data set. For additional details, please refer to Chapter 2 and Appendix A.