

2. Study Methods
In this chapter, we describe the research methods used in this study. We first present the definitions of HSR and PCR that were used to identify relevant federally supported research projects and to develop a research domain framework to categorize projects according to key health services and primary care topics. We next describe the Federal Advisory Group and technical review process that AHRQ and the RAND team developed to guide the study.
We then review the data collection and analytic methods used to answer the study’s research questions. As noted in Chapter 1, these included three primary data collection methods:
- Two TEPs constituted of stakeholder leaders in the fields of HSR and PCR, respectively.
- Interviews with key informants from five stakeholder groups in HSR and PCR.
- An environmental scan and portfolio analysis of federally funded HSR and PCR extramural projects from October 1, 2011, through September 30, 2018.
After describing the data collection methods, we discuss the qualitative methods used to analyze the themes identified by TEP and interview participants and the quantitative methods used to analyze the data set of federally funded research projects collected through the environmental scan. We conclude the chapter with a discussion of the limitations of the study methods.
Definitions of HSR and PCR
The study team worked iteratively with AHRQ and the study’s TEPs to develop and operationalize definitions of HSR and PCR based on concepts in the literature but tailored to the needs of the study.
The definition of HSR used in the study is based on Lohr and Steinwachs (2002):
A multidisciplinary field of scientific investigation that studies how social factors, financing systems, organizational structures and processes, health technologies, and personal behaviors affect access to health care, the quality and cost of health care, and ultimately, our health and well-being.
For purposes of the study, the definition of health care broadly encompasses health, mental health, substance abuse, and long-term care services, as well as social and other services as they connect to health care. In addition, the HSR definition above emphasizes inputs or antecedents of health care (e.g., social factors, financing systems, organizational structures and processes, health technologies, and personal behaviors) and how they affect and produce outputs or outcomes of health care (e.g., access to health care, the quality and cost of health care, and ultimately, our health and well-being). Thus, the HSR definition for this study excludes research on the inputs or outputs of health care that does not also examine their relationship to the provision or delivery of health care—for example, a study that exclusively focuses on the availability of healthy food options in communities, trends in national health care expenditures, or epidemiology of the prevalence of diseases or health status without attention to how these factors affect or are affected by health care services. Lastly, given the above concentration on scientific investigation, the study’s HSR definition excludes narrow program monitoring and accountability reporting that is not intended to contribute to broader scientific knowledge and understanding of health services.
The definition of PCR used in this study consists of research that addresses primary care as defined by the Institute of Medicine (IOM) (1996):
The provision of integrated, accessible health care services by clinicians who are accountable for addressing a large majority of personal health care needs, developing a sustained partnership with patients, and practicing in the context of family and community.
The study’s definition also specifically encompasses the research areas defined in the legislation that establishes AHRQ as the statutory home for PCR in HHS. The statute calls for research concerning: (a) the nature and characteristics of primary care practice; (b) the management of commonly occurring clinical problems; (c) the management of undifferentiated clinical problems; and (d) the continuity and coordination of health services (42 U.S.C. 299 et seq). Expanding on the IOM definition of family and community, we additionally include the role of primary care providers and systems in addressing community health needs and social determinants of health (Park et al., 2018; American Academy of Family Physicians, 2019; Artiga and Hinton, 2018; Advisory Committee on Training in Primary Care Medicine and Dentistry, 2016).
We note that, under this definition, PCR includes research on the delivery of primary care that overlaps with HSR, as well as other research related to primary care, such as clinical studies of common conditions in primary care without a health services component (Starfield, 1996).
Research Domain Framework of HSR and PCR
The study team also worked iteratively with AHRQ and the study’s TEPs to develop a conceptual framework of HSR and PCR domains in order to differentiate the types of research funded across federal agencies and to support the identification of gaps in research. The framework includes four domains of health care “outputs” typically of interest to health care policymakers and other stakeholders (Quality of Care, Access to Care, Health Care Costs and Utilization, and Equity of Care), four domains of health care “inputs” (Organization of Care, Financing of Care, Social Factors, and Personal Preferences and Behavior), and a domain of research methods and tool development (MTD) integral to the advancement of HSR and PCR and implementation of research evidence into practice (Figure 2.1). Below we provide short descriptions of each domain.
Figure 2.1. Research Domain Framework for HSR and PCR
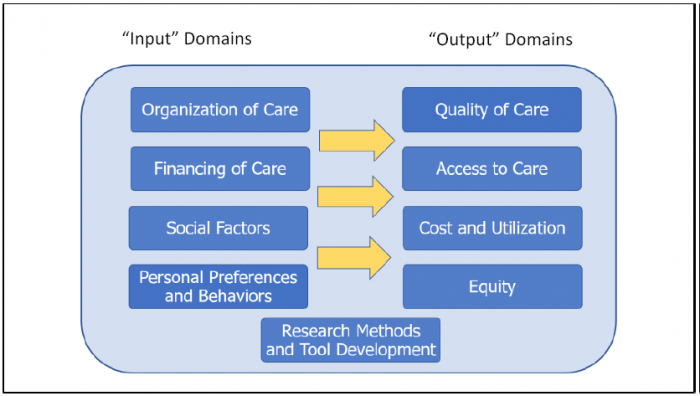
The domains for “inputs” of health care include the following:
- Organization of Care. Structures and routines of care and the process of how they change or improve, from the composition and functioning of care teams to the composition and dynamics of health care delivery systems and markets, including both social (e.g., workforce, clinician, and staff experience) and material assets (e.g., health technologies, physical facilities).
- Financing of Care. Programs and mechanisms for determining how health care organizations and professionals are paid to deliver care.
- Social Factors. Social, economic, and community determinants of health.
- Personal Preferences and Behaviors. Health-related behaviors (e.g., diet, exercise, and other lifestyle factors, care seeking, adherence to therapy), knowledge of health care and health conditions, and preferences for care and involvement in care decisionmaking.
The domains for “outputs” of health care include the following:
- Quality of Care. Assessments of care process as well as intermediate and definitive outcomes of care, including provision of recommended care, clinical control of chronic conditions such as hypertension or asthma, patient safety, patient experience, health-related quality of life and mortality.
- Access to Care. Geographic availability of providers, having a usual source of care, ability to receive care in person or remotely in a timely manner, or having adequate health insurance coverage.
- Cost and Utilization. Resource use in terms of costs and expenditures, utilization of treatments and services, and value (i.e., relative cost per unit of quality or outcome).
- Equity. Differences in quality, access, or cost and utilization of care across populations, and improvement of these outputs particularly for vulnerable or underserved populations.
The domains for MTD include Health Information Technology (HIT) Applications and Tools (e.g., design and testing of telehealth, mobile, EHR clinical decision support systems, and other functionality), Model Development and Validation (e.g., psychometric instruments, risk prediction models), Toolkit Development (i.e., documented strategies and materials to facilitate implementation of health care interventions or best practices), Evidence Review and Synthesis (i.e., systematic reviews of health care research findings), and Simulation Modeling (i.e., mathematical models incorporating simulated inputs to examine or predict health care processes or outcomes).
Research Subcategories of Interest
In addition to the research domains above that provided a framework for categorizing HSR and PCR projects, the study team, with feedback from AHRQ and the study’s TEPs, identified research subcategories of interest that represented important specific health care outcomes or research areas expected to differentiate HSR and PCR supported by different federal agencies. Two categories—Patient Safety (e.g., medical errors, harms produced by health care) and Definitive Health Outcomes (e.g., mortality, health-related quality of life)—primarily reflected “deeper dive” subcomponents within the Quality of Care research domain, while three others reflected specific cross-cutting categories of research—Aging, Pediatrics, and Prevention.
Details on how these research domains and subcategories were further defined and operationalized for the environmental scan and portfolio analysis are provided below and in Appendix B.
Study Advisory and Technical Review Process
AHRQ and the RAND team developed a Federal Advisory Group and a technical scientific review process specifically to guide this study.
Federal Advisory Group
AHRQ formed a Federal Advisory Group for the study consisting of representatives from seven federal agencies and operating divisions with key interests and funding programs in HSR and PCR. These agencies and operating divisions included six from HHS—AHRQ, Office of the Assistant Secretary for Planning and Evaluation (ASPE), Centers for Disease Control and Prevention (CDC), Centers for Medicare and Medicaid Services (CMS), National Institutes of Health (NIH), Office of the National Coordinator for Health Information Technology (ONC)— and one from the VA, the Veterans Health Administration (VHA).
The purpose of this advisory group was to provide feedback on the design and preliminary results of the study, as well as aid in identifying and collecting relevant data on HSR and PCR projects within agencies as discussed later in the methods for the environmental scan and portfolio analysis. The Federal Advisory Group met via teleconference on three occasions to receive updates on study progress and discuss the overall study design and plan for the environmental scan (December 2018), preliminary results of from the TEPs, interviews, and environmental scan and portfolio analysis (April 2019), and prioritization processes for HSR and PCR gaps (June 2019).
Technical Review Process
To ensure the scientific rigor of the study and mitigation of any potential bias in the research, the RAND team instituted an expanded, ongoing technical review process. This process included three technical reviewers, two reviewers from outside RAND with expertise in HSR and PCR, and one RAND reviewer not part of the study team with expertise in health care as well as research similar to this study in education and other fields. The reviewers provided ongoing feedback on study decision points and interim products during the project through group teleconference review sessions to enable rapid and efficient feedback. Teleconference sessions reviewed the overall study design, study participant sampling process, design of the environmental scan, and draft interview guides (November 2018), the proposed list of TEP members and first TEP meeting agenda and discussion guides (January 2019), the second and third TEP meeting agendas and discussion guides (March and April 2019, respectively), and preliminary TEP and interview results (June 2019). The RAND team followed up each session with written responses to reviewer comments and revisions made to protocols and materials.
In addition, the technical reviewers provided written reviews for two study document deliverables, a draft Environmental Scan and Portfolio Analysis Report (January 2019) and a draft of this Comprehensive Report (September 2019). The RAND study team followed up with written responses to reviewer comments and document revisions to all technical reviewers, whose formal approval was required before the documents could be finalized.
Data Collection and Analytic Methods
Study Participant Sampling for the Technical Expert Panels and Interviews
The RAND team compiled a combined sampling pool of potential study participants to use for both the TEPs and stakeholder interviews. Individuals included in this sampling pool were identified through four primary sources: nominations from stakeholder organizations representing different interests in conducting and using HSR and PCR, members of previous TEPs on HSR and PCR conducted by various organizations, members of existing advisory panels on HSR and PCR, and nominations from select RAND professional staff of individuals from organizations outside RAND with areas of expertise relevant to the research questions.
Potential interview participants were identified from this sampling pool for four of the five interview stakeholder groups: (1) HSR and PCR researchers, (2) health care delivery system leaders, (3) other users of HSR and PCR, and (4) state-level health care policymakers. The study team also conducted additional outreach to associations of state-level stakeholders to augment the pool of potential interview candidates for this stakeholder group. In each of these four groups, our aim was to select individuals representing diverse backgrounds; for example, in the health care delivery system leaders group, we selected individuals from different types of systems of various size, ownership, and geographic location as noted below.
The study team developed a separate sampling procedure for the fifth interview stakeholder group—federal HSR and PCR leaders. Agency representatives in the study’s Federal Advisory Group, described above, as well as points of contact at other agencies, were asked to nominate potential interview candidates knowledgeable about the portfolios of HSR and PCR funding within their agencies.
The total sampling frame for the study’s TEPs and interviews consisted of 253 individuals. These included nominations from 23 stakeholder organizations. As described below, TEP members were recruited first, then participants for the stakeholder interviews.
Technical Expert Panels
The purpose of the TEP meetings was to convene individuals with expertise in research, policy, and the use of HSR and PCR to provide group-facilitated perspectives on the study’s key research questions, as well as feedback on methods and preliminary results from other tasks.
Technical Expert Panel Structure and Selection
The study team identified specific stakeholder roles to include in the TEPs to ensure inclusion of the range of relevant HSR and PCR stakeholder perspectives. In conjunction with AHRQ, the study team refined the three primary roles for the TEPs to include perspectives from (1) researchers, (2) health care delivery system leaders, and (3) other users of research. Within each of these primary roles, the team further specified secondary roles to be represented on each TEP, as shown in Table 2.1.
Individuals on the list of potential TEP members that had been generated using the sampling method described above were then grouped according to the primary and secondary stakeholder perspectives required for each TEP.
Table 2.1. Primary and Secondary Roles for Technical Expert Panel Members
| Primary Role | Secondary Roles: HSR TEP | Secondary Roles: PCR TEP |
|---|---|---|
| Researchers | HSR expert (clinical background), HSR expert (nonclinical background), disparities, patient safety | Family practice, internal medicine, pediatrics, geriatrics, disparities |
| Health care delivery system leaders | Large integrated health system, safety net health system, small community-based rural hospital or health system, and/or academic medical center | Community health center organization, large primary care medical group, small or rural primary care practice |
| Other users of research | Insurer executive, consumer representative | Insurer executive, consumer representative |
To further ensure a range of perspectives, the RAND team developed a set of criteria for balancing the overall composition of each TEP and selecting among the potentially large number of candidates for each TEP role. The balance criteria included:
- Range of expertise (specialties within HSR or PCR, medical and allied health professionals, patient safety, disparities, pediatrics, and other areas).
- Breadth of funding (whether the potential member is solely funded by one agency and/or has a differently funded portfolio).
- Avoidance of potential conflicts of interest (e.g., current RAND employment, prior key role at AHRQ).
- Geography (regional areas as well as rural/urban settings).
- Representation of underrepresented groups (particularly gender and race/ethnicity).
- Newer perspectives (individuals who might not have participated in similar TEPs/interviews on multiple prior occasions, or who have unique perspectives).
Individuals were selected and invited with the goal of obtaining a diversity of perspectives using these criteria. First-choice candidates who declined were replaced by other candidates to maintain balance across criteria on each TEP. Of the 39 individuals invited to participate in the HSR TEP, 9 (23 percent) accepted. Of the 21 individuals invited to participate in the PCR TEP, 11 (52 percent) accepted. Scheduling conflicts were the most common reason for declining participation, particularly given the short time between the commencement of invitations in mid-December 2018 and the scheduled dates for the first TEP meetings in January 2019.
To increase the breadth of perspectives included in the study overall, participants could be included in either a TEP (HSR or PCR) or an interview, but not both. TEP selection was completed first, and all individuals who declined to participate in a TEP were asked whether they would be willing to be considered for the stakeholder interviews.
Technical Expert Panel Meetings
Each TEP met three times during the study. TEP meetings were facilitated by senior study team members based on a structured discussion guide. In addition to providing feedback on study methods and preliminary results from other tasks, the TEPs discussed the study’s key research questions over the course of the three meetings. The first meeting of each TEP discussed the breadth and focus of federal agency research portfolios in HSR and PCR, overlap and coordination of agency HSR and PCR portfolios, and the impact of federally funded HSR and PCR. The second meeting of each TEP discussed research gaps in HSR and PCR and prioritization of gaps. The third meeting of each TEP continued the topics of research gaps and prioritization, as well as discussed recommendations to improve the federal HSR and PCR enterprise. Copies of the TEP discussion guides are available upon request from the study team.
The first TEP meetings were held in person separately for HSR and PCR, respectively, on January 22 and 23, 2019, each lasting approximately eight hours. The second and third meetings for each TEP were held via teleconference calls lasting two hours on April 1 and 2, 2019, and then May 6 and 7, 2019, respectively. After each set of meetings, the RAND team analyzed summary notes and transcripts to extract key themes that were synthesized as part of forming the initial codebook for the qualitative thematic analysis of TEP and interview data as described below.
Stakeholder Interviews
The purpose of the stakeholder interviews was to provide balanced, in-depth input across a wider range of stakeholder perspectives on the key study questions. These perspectives included the five stakeholder groups specified in the study’s statement of work: (1) HSR and PCR researchers, (2) health care delivery system leaders, (3) other users of HSR and PCR (e.g., consumers, purchasers, insurers, and improvement organizations), (4) state-level health care policymakers, and (5) federal HSR and PCR leaders.
Interview Selection and Recruitment
Individuals from the sampling pool described above who did not participate in a TEP were purposefully selected for the interviews. The study team identified a set of eight to ten first-choice candidates and similar alternates for each stakeholder group in order to include a breadth of perspectives within and across the five interview stakeholder groups using similar balance criteria as for the TEPs.
Recruitment for interviews was conducted via email invitation followed up by email and telephone calls. First-choice interview candidates who declined were replaced by one of the alternates for their stakeholder group. Choice of alternates depended on the characteristics of the person being replaced and the range of expertise and backgrounds of interview candidates who had already agreed to participate. Recruitment for each stakeholder group continued until at least eight participants had been recruited within each group.
A total of 50 individuals participated in the interviews. Thirty-three individuals who were invited declined to participate,1 yielding an overall acceptance rate of 60 percent. Table 2.2 presents the number of interviews conducted in each stakeholder group, with additional detail on stakeholder expertise included within each group. Table 2.3 displays the relative geographic diversity of the interview sample across stakeholder groups.
Table 2.2. Interviews Conducted by Stakeholder Group
| Stakeholder Group | Total Interviews | Stakeholder Group Details |
|---|---|---|
| Researchers | 10 | PCR (2), HSR (2), health economics, nursing, geriatrics, patient safety, disparities, behavioral health |
| State-level policymakers | 9 | State and local health departments (3), state-level private insurers and purchasers (2), state hospital association, state primary care association, state improvement org, state policy expert |
| Delivery system leaders | 8 | Private integrated health systems (3), academic medical system, urban safety net hospital system, physician group association, regional safety net health center system, behavioral health system |
| Other research users | 10 | Consumer groups (3), purchasers (2), health services policy experts (3), improvement and accreditation orgs (2) |
| Federal research leaders | 13 | AHRQ (2), ASPE, CDC, CMS (2), HRSA, NIH (3), ONC, SAMHSA, VHA |
| Total | 50 |
Table 2.3. Interviews Conducted by Geographic Region
| Geographic Region | Research | State-Level Policy Makers | Delivery System Leaders | Other Research Users | Federal Research Leaders | Total Interviews |
|---|---|---|---|---|---|---|
| Northeast | 4 | 2 | 2 | 2 | 0 | 10 |
| Midwest | 2 | 2 | 2 | 1 | 0 | 7 |
| West | 2 | 4 | 3 | 1 | 0 | 10 |
| South | 2 | 1 | 1 | 6 | 13 | 23 |
| Total | 10 | 9 | 8 | 10 | 13 | 50 |
1. Individuals who declined interviews included eight researchers, seven state-level policymakers, nine delivery leaders, seven other research users, and four federal research leaders.
Interview Guide Development and Data Collection
The study team developed three sets of interview guides—one for the HSR and PCR researcher stakeholder group; one for the federal HSR and PCR leaders’ stakeholder group; and one applicable to the health care delivery system leaders, state-level health care policymakers, and other users of HSR and PCR stakeholder groups. Each interview guide covered all five key research questions for the study. Question wording and probes were tailored to the context and expertise of the stakeholders included in each guide. Copies of the interview guides are available upon request from the study team.
Study team members met weekly to debrief on stakeholder recruitment and interview data collection. Interviewers reflected on respondent comprehension of interview questions and information being yielded, and the team modified phrasing and items to emphasize in the discussion guides when needed.
Interviews were semistructured and lasted approximately an hour. Each interview was conducted via telephone by a study investigator experienced in qualitative data collection, and all interviews were audio-recorded (with permission) and transcribed for analysis, except one for which detailed manual notes were used in the analysis.
Thematic Analysis of Technical Expert Panel and Interview Data
Four study team members skilled in qualitative analysis developed the thematic coding scheme, coded the TEP and interview transcripts, and summarized the themes. The study team developed an initial codebook based on the main topics in the interview guides corresponding to the study research questions (Table 1.1), emergent themes identified from team reflections on the initial interviews and interview transcripts from each stakeholder group, and review of themes from the first TEP meeting notes.
The four team members then test-coded for all initial themes in two interview transcripts selected for their extensive responses across interview questions. The team members discussed and resolved discrepancies in coding by consensus, with changes to coding definitions and procedures updated in the codebook. Three team members then coded the remaining TEP and interview transcripts using the Dedoose qualitative analysis software platform (SocioCultural Research Consultants, 2018). The four team members met weekly to review coding questions, refine coding definitions, and explore potential new codes that emerged during analysis.
The summarization of themes was organized around the study research questions, with individual team members assigned as the lead for summarizing the codes for a research question across interviews using a common template. Each lead reviewed the quotations coded for their research question and compiled a bulleted summary of key themes, exemplar quotes for each theme, and the number and types of stakeholders who identified that particular theme. A second team member reviewed the bulleted summary for organization and completeness, followed by other members of the qualitative analysis team, who also reviewed quotes not included in the initial bulleted summary for potential relevance. The summaries were then used as the basis of the results text for corresponding sections of the report.
In the results text, we report key themes, that is, themes that were raised by multiple study participants within a stakeholder perspective or across stakeholder perspectives (i.e., one of the stakeholder interview groups, the HSR TEP, or PCR TEP). Quotes provided in the text are examples from those participants. On occasion, we report a theme reported by a single participant when relevant, which is indicated in the text.
Environmental Scan and Portfolio Analysis
The purpose of the environmental scan and portfolio analysis (or “scan”) was to catalog a data set of federally sponsored HSR and PCR projects, collect and derive indicators needed to differentiate types of HSR and PCR projects, and produce quantitative analyses of the breadth and focus of HSR and PCR portfolios across federal agencies.
Scope of the Scan
The scope of federal HSR and PCR projects covered in the scan was delimited on three parameters: the federal agencies included, the time frame of when federal HSR and PCR projects were funded, and funding mechanisms.
Federal Agencies Included
AHRQ’s statement of work for the study specified the agencies in the scan to include the 11 operating divisions within HHS, plus the VA. The operating divisions of HHS are as follows:
- Administration for Community Living (ACL).
- Administration for Children and Families (ACF).
- AHRQ.
- Agency for Toxic Substances and Disease Registry (ATSDR).
- CDC.
- CMS.
- Food and Drug Administration (FDA).
- Health Resources and Services Administration (HRSA).
- Indian Health Service (IHS).
- NIH.
- Substance Abuse and Mental Health Services Administration (SAMHSA).
In addition, two specific offices within the Immediate Office of the Secretary were identified for inclusion—ASPE and ONC. Within the VA, the scope covered HSR and PCR funded by the VHA. HSR and PCR projects funded by the Department of Defense or the Patient-Centered Outcomes Research Institute (PCORI, a nongovernment institute established by the 2010 Patient Protection and Affordable Care Act) are not included in the scan.
Time Frame of Funding
AHRQ’s statement of work for the study specified that the scan include federally funded HSR and PCR projects with funding start dates between FY 2012 and FY 2018, which correspond to the calendar dates October 1, 2011, through September 30, 2018. Projects with funding start dates prior to October 1, 2011, are not included in the scan, even if their periods of performance continue into the study period.
Funding Mechanisms
The scan included HSR and PCR projects funded through both research grant and contract mechanisms. Grant projects typically allow researchers broad discretion to propose a specific study design to address a general topic, which is then assessed by other researchers in a scientific peer review process. Contract projects typically entail a more specified predefined statement of work, set of deliverables, and monitoring of the research by federal agencies, with agency staff assessing and awarding contract proposals often on shorter timelines than the grant peer review process.
The scan also included only extramural research, that is, funding of research conducted by nonfederal institutions, since the structure and data for intramural research conducted by agency staff were determined to be too variable across agencies to feasibly characterize in a systematic manner within the time and resources available for the scan. However, the report characterizes intramural research using qualitative data from the study’s two other primary data collection tasks—TEPs and stakeholder interviews. The study focused on intramural research that is internally vetted with the intention of being released or published more broadly for external stakeholders and does not include other analyses conducted by agencies solely for use by policy and decisionmakers within the federal government.
Per the study’s aims to characterize funding for studies that examine a research question intended to contribute to scientific knowledge on an HSR or PCR topic, the scan did not include extramural funding for research infrastructure related to research education and training (e.g., career awards), conferences and workshops, or research center grants that only included funding for research support but not specific studies. Although such funding is important to supporting the HSR and PCR enterprise, they were not considered research projects per se for purposes of this study. However, successful applications for research funding that were supported by these research infrastructure activities would be included in the scan as separately funded projects.
Likewise, per the research definitions presented previously in the chapter, the scan excludes service grants or other projects in which evaluation components focus exclusively on program monitoring or accountability and are not intended to contribute to broader scientific study and understanding of health services or primary care.
Adjudication of Projects for Inclusion in the Scan
In addition to falling within the above scoping criteria, a project had to be adjudicated as addressing HSR, PCR, and/or MTD to be considered as in-scope for the scan.
HSR Adjudication
To ensure that projects included as HSR in the scan focused on the delivery and provision of health care services per the study’s definition, the scan required that projects adjudicated as HSR fulfill at least one of two conditions: (a) address at least one of three “output” domains (Quality of Care, Cost and Utilization, or Equity) and at least one of the “input” domains, or (b) address the Organization of Care “input” domain. The Access to Care output domain was not included in condition (a) since this domain was developed later than the other domains and implementation of the HSR adjudication criteria, and was generally coded to projects together with at least one other output domain, such as Quality of Care or Equity, that would ensure the projects’ inclusion in the scan as HSR.
PCR Adjudication
Projects were identified as meeting the study’s definition of PCR through a separate assessment based on whether it addressed primary care professionals, services, or settings, regardless of whether it also met any of the adjudication criteria above for HSR. This process ensured that the scan would include PCR projects that do not overlap with HSR, as well as PCR projects that do.
Methods and Tool Development Adjudication
Similarly, MTD projects were identified through a separate assessment of whether a project met the definitions for at least one of the five MTD categories (i.e., HIT applications and tools, model development and validation, toolkit development, evidence review and synthesis, and simulation modeling). Many projects were adjudicated as MTD were also adjudicated as HSR and/or PCR.
As described above, an individual project could be determined to meet all or none of these three in-scope adjudication classifications and are thus not mutually exclusive. For detailed definitions, coding specifications, and adjudication procedures for research domains and in-scope criteria, go to Appendix B.
Data Sources
The environmental scan drew on two primary data sources: publicly available databases of federally funded grant projects, and contract and grant data provided to RAND directly by federal agencies.
Public Databases of Federally Funded Research Projects
The largest source of data for the environmental scan—and the primary source of grant project data—consisted of the publicly available NIH Research Portfolio Online Reporting Tools (RePORTER) database. Although developed and managed by NIH, the RePORTER database includes grant projects funded by agencies across HHS as well as the VA (National Institutes of Health, 2017a).
The study team also reviewed the Health Services Research Projects in Progress (HSRProj) database developed by AcademyHealth and the University of North Carolina at Chapel Hill (AcademyHealth, undated; U.S. National Library of Medicine, 2019a), as well as agency-specific project databases, including the AHRQ Project Research Online Database, the AHRQ HIT portfolio website, and the HRSA grant database (Agency for Healthcare Research and Quality, undated-c; Agency for Healthcare Research and Quality, undated-d; Health Resources and Services Administration, undated-a). These databases were not found to contain any in-scope projects that were not already present in RePORTER, though the AHRQ Project Research Online Database and HSRProj were found to contain supplemental information (notably project abstracts and topic lists) that was merged into the consolidated scan data set. The study team also reviewed other federal grant data sources, including HHS’s Tracking Accountability in Government Grants System, Grants.gov, and the Office of Planning, Research and Evaluation Resource Library, though these were not found to provide any additional project-level data for the scan.
Agency-Provided Data on Research Projects
As mentioned previously in the chapter, the study’s Federal Advisory Group aided in the identification and collection of relevant data on HSR and PCR projects within agencies. In particular, the representatives from the agencies in the advisory group (AHRQ, ASPE, CDC, CMS, NIH, ONC, and VHA) helped describe and identify relevant HSR and PCR portfolios and data sources for inclusion in the scan, identify other points of contact within their agencies knowledgeable about specific HSR and PCR funding areas, and obtain needed data on relevant HSR and PCR agency projects not available from public sources, especially contract projects. The representatives also provided feedback via “member checking” of preliminary scan results for the HSR and PCR projects in their respective agencies. This feedback was used to refine the scan methods and analysis but did not constitute endorsement of scan results by agency representatives.
AHRQ additionally identified and initiated contact with representatives of other federal agencies within the scope of the scan for similar assistance. Representatives from five of these agencies responded, including ACL, ATSDR, FDA, HRSA, and SAMHSA.
Data Sources by Agency
Data on extramural research grants, including those from NIH, AHRQ, CDC, VHA, ACF, and FDA, were derived from the NIH RePORTER database. Data on extramural research contracts and grants were provided directly by several funding agencies: AHRQ provided data n its relevant extramural research contracts; CDC on relevant extramural research grants and cooperative agreements; CMS on relevant extramural research contracts from two divisions— the Center for Medicare and Medicaid Innovation (CMMI) and Center for Clinical Standards and Quality (CCSQ); VHA on relevant research grants from its Health Services Research and Development and Quality Enhancement Research Initiative programs; and ACL on relevant research grants from its National Institute on Disability, Independent Living, and Rehabilitation Research (NIDILRR).
Representatives for ASPE and HRSA provided descriptions of the HSR and PCR funded by their agencies but were not able to provide systematic data on extramural research projects for the scan analysis in time for this study. Representatives for ACF did not respond in time to be included in the study. Representatives for FDA, HRSA, IHS, ONC, SAMHSA, and ASTDR confirmed that these agencies do not regularly fund extramural HSR or PCR projects per the definitions of this study.
Challenges Collecting Federal Contract Project Data
Collecting project-level data on contracted extramural research proved highly challenging, since data systems for federal contracts are neither designed nor suited to identify research projects, let alone HSR- and PCR-related projects. These contract databases also tend to provide less information about the content of research projects needed to distinguish domains and categories of research, compared with the RePORTER and other grants databases that are designed to catalog and describe federally funded grant projects.
This required the study team to rely on agencies to identify and provide contracted projects. However, given the structure of the available federal contract databases, this task proved challenging to agency staff as well, and was one reason some agencies could not provide project-level data for the study’s environmental scan and portfolio analysis. Other agencies that were able to provide comprehensive project-level data for contracted research either had developed separate internal research databases for tracking contract projects or expended considerable effort to compile data on HSR and PCR contracts for the study. This process also required frequent iteration between the study team and agency staff to obtain additional details for project descriptions in order to adequately adjudicate research domains and categories.
Scan Data Set Elements
The study team identified a set of core data elements to collect on each research project in the scan in order to characterize the portfolios of HSR and PCR funding, as listed below. Project descriptive information, such as the project title, descriptive narrative or abstract, and any keywords or topical categories, was important to differentiate projects by content area and type of research. This information included the main research domains and specific categories of research described previously, as well as health care or community settings and clinical conditions (if applicable). Other project information needed for the scan database included administrative information on funding mechanisms, funders, and funded institutions, as well as the period of performance and level of effort.
Project Descriptive Information
- Project reference number (if applicable).
- Project title.
- Project descriptions, narrative, and/or abstract.
- Keywords and/or topical categories (if available).
Project Administrative Information
- Funding mechanism (grant or contract type).2
- Grant or contract number.
- Lead project funder (agency, program, point of contact).
- Other project funders.
- Lead and other funded institution.
Project Period of Performance and Level of Effort
- Project start date.
- Project end date.
- Funding amount.
2. For a list of grant activity codes in the NIH RePORTER database related to research infrastructure that were excluded from the scan, go to Appendix B.
Scan Analytic Approach
The scan analysis relied on a combination of manual and automated reviews of project descriptions to categorize each project according to the research domain framework presented earlier in this chapter. Manual reviews were conducted on agency-provided projects as well as a sample of the projects from the RePORTER research grants database. These manual reviews were used to train a natural language processing and machine learning algorithm to automate classification of the remaining RePORTER project records that were not manually reviewed. Details of these steps are provided below.
Manual Reviews of Projects
The study team manually reviewed over 3,000 projects to determine whether they met the criteria for the various categories within the research domain framework (i.e., the overall HSR, PCR, and MTD classifications, the eight HSR and PCR domains, the five research MTD categories, and/or the five research subcategories of interest). The team discussed approximately 20 percent of these reviews. These discussions were crucial to iteratively refining the research domains and categories of the framework and ensuring interrater agreement.
Four researchers on the study team participated in the manual reviews. These reviews included all agency-provided project records as well as both targeted and randomly sampled projects from NIH RePORTER. Projects were selected for targeted reviews on the basis of an initial determination that they were likely to be in-scope for our scan according to one or more of the following criteria: (a) being present in the HSRProj database, which is manually curated to include HSR projects; (b) being tagged in the HSRProj database with Medical Subject Heading terms (U.S. National Library of Medicine, undated; U.S. National Library of Medicine, 2019b) related to specific categories in the research domain framework; (c) being tagged with the term “health services” in the RePORTER database’s Research, Condition, and Disease Categorization list (National Institutes of Health, 2018); or (d) being identified as likely in-scope in preliminary results from the machine learning algorithm described below. Projects were also randomly sampled from the RePORTER database in order to provide a representative set of out-of-scope projects to include when training the machine learning algorithm.
A subset of these projects was independently reviewed by two team members in order to compare results and identify potential sources of inconsistency in the framework definitions and classification rules or their application. These independent reviews of the same projects were also used to calculate interrater agreement for each of the research categories within the framework. Independent reviewers agreed 93 percent of the time on whether a project was overall within the scope of the scan framework (i.e., meeting the criteria for HSR, PCR, and/or MTD classification), with an interrater reliability kappa of 0.86 (ranging from –1.00, lowest reliability, to 1.00, highest reliability). Reviewers agreed on specific research domains and categories ranged between 79 percent and 100 percent of the time, with kappas from 0.43 to 1.00.3 In cases in which two reviewers disagreed, a third reviewer was enlisted to provide an additional opinion; this, together with group discussion, was used to produce a final coding determination.
3. For details on interrater agreement and reliability of manual reviews, go to Appendix A.
Machine Learning Adjudication of Research Domains and Categories
Automated classification algorithms are frequently used to analyze large amounts of text data that would be infeasible to completely review manually, such as the descriptions of projects in this study’s scan data set (Sebastiani, 2002). Previous efforts to analyze federally funded research portfolios have relied on various forms of automated algorithms, including search-termbased logical rulesets, unsupervised clustering, and supervised machine learning (Wilczynski et al., 2004; Freyman, Byrnes, and Alexander, 2016; Villani et al., 2018). Similarly, within the RePORTER database, NIH applies an automated “text-mining” algorithm to project descriptions to determine the Research, Condition, and Disease Categorization for project records.
As described below, we drew on these and similar efforts to automate our analysis of the roughly 90,000 project descriptions we did not manually review. To do this, we relied on natural language processing to map project descriptions onto indices of relevant words and phrases, and then input those indices into a machine learning model to classify projects according to our research domain framework (Sebastiani, 2002). As in other supervised learning approaches, we treated the manual reviews as “gold-standard” classifications to both train the machine learning model and validate its accuracy (Wilczynski et al., 2004; Villani et al., 2018).
The machine learning algorithm used the narrative text found in the project abstract or description field to generate classification scores for each project and category based on a logistic regression model. We applied a straightforward natural language processing approach to these project descriptions, namely a “bag of words” method, which treats frequently occurring words and two-word phrases as unrelated objects. The algorithm was run five separate times following a stratified K-fold cross-validation approach, with one-fifth of the manually reviewed data reserved each time in order to test algorithm accuracy and identify false positives and false negatives, leaving the algorithm to be trained on the other four-fifths of the manually reviewed data (Kohavi, 1995). While the algorithm is imperfect and thus classifies some projects incorrectly, it was calibrated to produce a similar number of false positives and false negatives in order to maximize the validity of the overall classification results reported in Chapter 3.
The results of our scan are presented in Chapter 3 and Appendix B. Manual classifications, as the “gold standard” upon which the algorithm classifications were based, were given precedence in calculating these results. Manual classifications were tallied first, and then combined with the algorithm classification results for projects that were not manually reviewed. Additional details on the number of reviews we conducted and on the machine learning methods are provided in Appendix A, together with measures of interrater agreement and algorithm accuracy.
The scan results we report in Chapter 3 are based on the number of projects, rather than funding amounts, due to data quality issues. Nearly 4 percent of the projects that were classified as in-scope for the study scan were missing funding information, with substantial variability across agencies and research domains. Federal stakeholders familiar with the funding amount data in the RePORTER database also noted challenges in validly calculating total project funding amounts, given complexities in aggregating across multiple project records of different types per project in the database. Since the purpose of the scan analysis was to examine the breadth of federally funded HSR and PCR and the types of projects funded by agencies across research domains and categories, the number of projects was considered an appropriate and more comprehensive metric.
Limitations of Study Methods
The sample of TEP and interview participants for the study was designed to provide a diverse range and depth of qualitative perspectives within and across stakeholder groups for federally funded HSR and PCR. We selected from five stakeholder groups for the interviews and from three stakeholder groups for the TEPs, while aiming for diversity within those groups as described above. However, it was not possible to guarantee that all possible perspectives were included. The sample of TEP and interview participants was neither designed nor intended to provide a representative distribution of perspectives among these sets of stakeholders.
For the environmental scan and portfolio analysis, we were not able to obtain comprehensive project-level data on extramurally funded research for all agencies in the study scope. This was due to various challenges related to limitations of existing federal data systems for tracking research contracts, and time and resource constraints for collecting project-level data of both agency staff and the study team. However, the study was able to collect comprehensive project-level data for six agencies, including those considered by stakeholders to be key extramural funders of federal HSR and PCR. In addition, the results of the environmental scan and portfolio analysis are sensitive to the definitions and consistency of the manual coding applied, as well as to the machine learning algorithms and specifications used. Consequently, we provide detailed information on the study’s machine learning methods, manual interrater reliability, and machine-adjudicated accuracy estimates in Appendix A, and on the study’s research domain definitions and specific coding rules in Appendix B.
The mixed methods approach of the study allowed using the strengths of the qualitative and quantitative methods to complement the limitations of the other. For example, the environmental scan and portfolio analysis was well suited to document the breadth and general distribution of HSR and PCR portfolios among agencies, but the qualitative data from the TEPs and interviews were better suited to understand the coordination among agencies and the impact of federally funded research. Both methods were integral in developing and refining the research domain framework.